-
PointNetSLAM & 3D AI 논문 정리 2022. 3. 19. 12:53
Title: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Authors : Charles R. Qi, Hao Su, Kaichun Mo and Leonidas J. Guibas
*모든 그림은 위 논문에서 발췌함
[1] Introduction
- 2D 이미지는 행렬이므로 특정 order에 의해 grouping 된 채로 얻어진다고 본다. 따라서 regular format이다.
- 반면에 3D point는 unordered, unstructured irregular format으로 얻어지기 때문에 일반적으로 polygon mesh나 volumetric voxel로 rendering 처리한 뒤 사용한다.
- Rendering 없이 point data를 직접 다루기 위해 다음 두 성질을 만족할 필요가 있다.
- Permutation invariant
- Point들이 unordered format이므로 network는 input order에 관계 없이 output이 같아야 한다.
- Interaction among points
- Point들은 distance metric 공간 안에 있다. 이것은 point가 인접 point들과 어떤 관계를 맺고 있음을 의미한다(독립이 아니며 어떠한 subset으로 구성). 이를 local feature라고 하며 network에서는 이 또한 학습되어야 한다.
- Rigid motion invariant
- Input transform (translation, rotation 등)에 관계 없이 output이 같아야 한다.
- Permutation invariant
- Problem Statement는 다음과 같다.
- Point cloud는 3D point $\{ P_i|i=1,... \ ,n \}$ 로 표현되며 $P_i$ 는 x,y,z 좌표 정보를 갖는다.
- Object classification 에서는 point cloud를 input으로 받아 k개의 class에 대한 점수를 추력한다.
- Semantic segmentation 에서는 한 개의 object 혹은 3D scene의 일정 부분을 input으로 받아 n개의 point들에 각각 m개의 semantic subcategories 점수를 출력한다.
[2] Methodology
- 해당 논문에서는 permutation invariant를 위한 3가지 전략(canonical order로 정렬, RNN 접근법, symmetric function) 중 symmetric function이 가장 결과가 좋다고 설명하고 있다. Symmetric function은 입력 순서에 상관없이 일정한 결과를 출력하는 함수이며 가장 간단한 예로 더하기와 곱하기 연산이 있다.
- 논문에서는 이 symmetric function을 적용하여 다음과 같이 일반 함수를 근사한다.
- $f(\{ x_1, ... \ , x_n \}) \approx g(h(x_1), ... \ , h(x_n))$
- $f:2^{\mathbb{R}^N} \rightarrow \mathbb{R}, \ h:\mathbb{R}^N \rightarrow \mathbb{R}^K$ and $g:\mathbb{R}^K \times \cdots \times \mathbb{R}^K \rightarrow R$
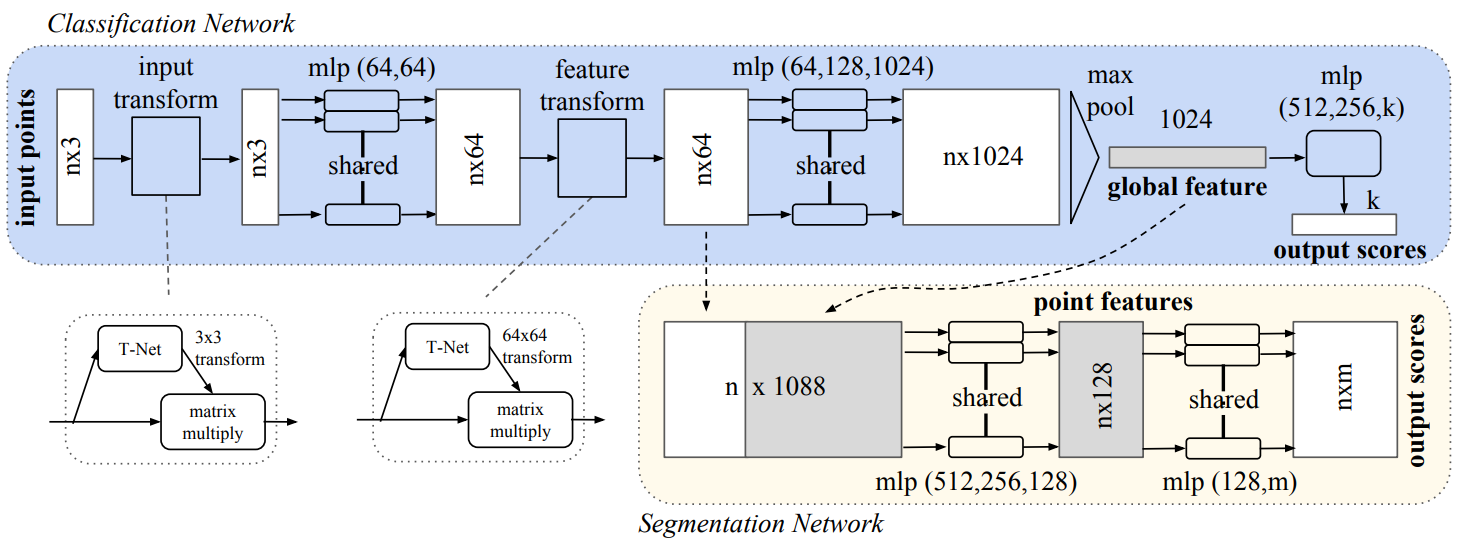
- $h$ : N차원 data vector를 K차원 local feature vector로 mapping. 다루고 있는 3차원 point data를 K차원 local feature vector로 mapping시키는 함수. 논문에서는 multi-layer perceptron networn (MLP)를 사용하여 $(n \times 3)$의 데이터를 $(n \times 64)$의 local feature 들로 근사한다. 즉, 3차원(N차원)의 data를 64차원(K차원)의 데이터로 확장하였다.
- $g$ : Symmetric function. $h(x_1), \cdots h(x_n)$ 들의 순서가 바뀌어도 $g$에 의한 출력은 일정하다. 논문에서는 max pooling을 사용한다. 64 채널의 local feature 들을 1024 채널로 확장하여 N개의 점에서 각 점마다 이를 모든 점에 대하여 i번째 feature를 기준으로 max값을 뽑아 이것을 global feature 라고 한다.
- Segmentation task에서는 global feature와 local feature가 함께 사용된다. 이 논문에서는 64개의 feature가 생성된 intermediate layer에 max pooling을 거쳐 생성된 1024개의 feature를 concatenate 시킨다.
- 해당 논문에서는 이 문제를 affine transformation(벡터 공간에서 직선과 평행을 보존하는 변환)을 추정하는 것으로 해결한다. 모델의 구조에서 input transform과 feature transform에 해당하는 mini-network 부분이 이것에 해당한다.
참고자료
[1] Qi, C., Su, H., Mo, K., & Guibas, L.J. (2017). PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 77-85.
'SLAM & 3D AI 논문 정리' 카테고리의 다른 글
LIO-SAM (0) 2022.04.01 Target-based LiDAR-Camera Calibration (0) 2022.03.19 ORB-SLAM 2 (0) 2022.03.19